
Kanthan Theivendran is a Consultant Orthopaedic Surgeon for Sandwell & West Birmingham Hospitals NHS Trust, where he also sits on the Research & Development Committee and is a Principle Investigator (PI) in a number of National Institute for Health and Care Research (NIHR) portfolio clinical trials. He is also an Honorary Professor at the School of Engineering and Applied Science at Aston University, and clinical lead for openOutcomes (an openEHR native Patient Reported Outcomes Measure (PROMs) digital platform)

Here, he shares his views and experience on the subject of data interoperability in the healthcare sector, and discusses the importance of an open-data platform approach for the advancement of healthcare data.
What is meant by healthcare data interoperability?
Healthcare data interoperability refers to the ability of different information systems, devices and applications to access, exchange, integrate and collaboratively use data in a coordinated manner, within and across organisational, regional and national boundaries, in order to provide timely and seamless portability of information and optimise the health of individuals and populations globally.
What are some of the biggest challenges in healthcare data interoperability?
Most medical professionals have experienced frustration when they have been unable to view patient information from local or neighbouring hospitals. Requests for notes – even when they are in a digital format (EPR/EHR) – take a long time, resulting in a patient journey which is delayed and sub-optimal. The healthcare data landscape is fragmented and siloed, and outside healthcare organisations – including other hospitals and primary care facilities – cannot easily access, view or update patient records, owing to a lack of interoperability between electronic health records (EHR).
In order for healthcare data to be universally available, an interconnected healthcare data architecture is essential. We need to put an end to data which is siloed across healthcare boundaries and organisations, and introduce universal standards relating to the way that healthcare data is stored and used.
It is relatively easy for individual software companies to create their own databases using proprietary software and applications, but the problem is the lack of standardisation: information can only be read and interpreted natively by the proprietary application which built it. In other words, the data is not interoperable with different applications in other healthcare settings (or sometimes even the same application of EPR/EHR used in another organisation), which means that a translator or adapter is required to send the message from one data store to another. And because healthcare data is complex and rich with information, it is extremely difficult to map across all the fine granular information from one siloed application to another. Although messaging standards such as HL7 FHIR (FHIR) do a reasonable job of translations and messaging, often the data is not detailed or granular enough, which means that information can be lost (due to its 80:20 rule). Also, FHIR is only a framework, rather than the specification itself.
In addition to these problems, there are also different meanings to stored information which cannot be easily interpreted by computers. We talk about semantics in healthcare data, which essentially describes the data and its meaning in the context of the healthcare data and its uses. This cannot be adequately described within messaging standards such as FHIR.
What are the solutions to the healthcare interoperability challenge?
One solution is a semantically interoperable standard such as openEHR. This is a data persistence standard that’s clinically modelled and represents the maximal data set, along with the meaning of that data, and forms the specifications. In order to get a truly interoperable healthcare data architecture, we need to build openEHR archetypes and clinical models with subject matter experts in the health and care community. These can be used for different use cases and different medical subspecialties, building an open library of archetypes and templates which can be developed and reused, no matter what the user’s commercial software application is.
openEHR acts as the foundation layer of standardised data. Unfortunately, it’s sometimes easier (and cheaper) and seen as a quick win to patch together siloed data with messaging standards (FHIR), but the problem is that this further fragments and siloes the healthcare data ecosystems without solving the interoperability problem.
The current healthcare data ecosystem is fragmented, so we need messaging standards such as FHIR to provide a connection between the data silos as an interim step, until we can deploy a true persistence data semantic standard such as openEHR.
We must start developing – in tandem – the data persistence foundation layer (openEHR) and creating the archetypes, clinical models and templates for all healthcare data uses, to get to the point of true interoperability. The continued patching of the data silos through messaging standards alone will not address core interoperability problems.
Tell us more about openEHR
The international standard in Electronic Health Records has been around for more than 20 years, during which time a community of clinical modellers has developed and stored an extensive library of clinical archetypes and templates in an open library called Clinical Knowledge Manager (CKM). These archetypes are being developed across the world and there are many countries using this data architecture, which also matches very closely with the FHIR profiles. Indeed openEHR and FHIR are complementary rather than competitors in the interoperability space.
FHIR was designed for the exchange of data between heterogeneous systems via APIs, messaging or as documents. It was not designed for the persistence of data.
openEHR provides a methodology for defining and curating clinical content and a specification of clinical data repository with an open API and query language that allows openEHR content to be stored and queried. It’s designed to support persistence, with built-in support for versioning and audit.
An open healthcare data platform approach
Healthcare data is the same as any other kind of data. In the same way that our smartphones use multiple apps to carry out specific jobs, there is no single healthcare app (EPR/EHR) that can do everything that we need. We use multiple web browsers such as Chrome, Firefox, Safari and more, and they all work seamlessly together, even transferring browsing history and favourite web pages at the touch of a button. Banking apps also work seamlessly together, integrating information from multiple banks into a single app. We can choose between different operating systems, web browsers and apps based on our preferences regarding user interface, functionality and user experience, which is made possible because there is a single web standard and universal specifications that all vendors must work to in order to create and sell their products. So, why shouldn’t we have the same rules in place for healthcare apps or EHRs/EPRs? Although healthcare data is considerably more complex and highly granular, the challenges are not insurmountable. We should be building a healthcare data standard fit for now and the future in order to overcome this fundamental problem of interoperability.
We need to move from an app-centric towards a data-centric healthcare open data architecture platform, underpinned by a data persistence layer such as openEHR, which can interoperate natively with any application. I would describe this as a ‘plug-and-play’ approach, without the need for complex transformation (curation) of data or messaging API’s/adapters to connect data silos. openEHR is a means to truly separate the application (software) from the data, allowing for an open data platform approach.
There are multiple standards in healthcare, including ICD11 for diagnosis, SNOMED-CT for medical terminology, IHE XDS for clinical documents, openEHR for structured electronic healthcare records, OMOP for standardised observational data for research, and FHIR for data exchange. All of these standards need to work together to provide a comprehensive standards set that can solve the interoperability challenge. A typical full healthcare data standards (FOXS) stack is shown below (adapted from John Meredith, Assistant Chief Architect Digital Health & Care Wales and openEHR International Board member):
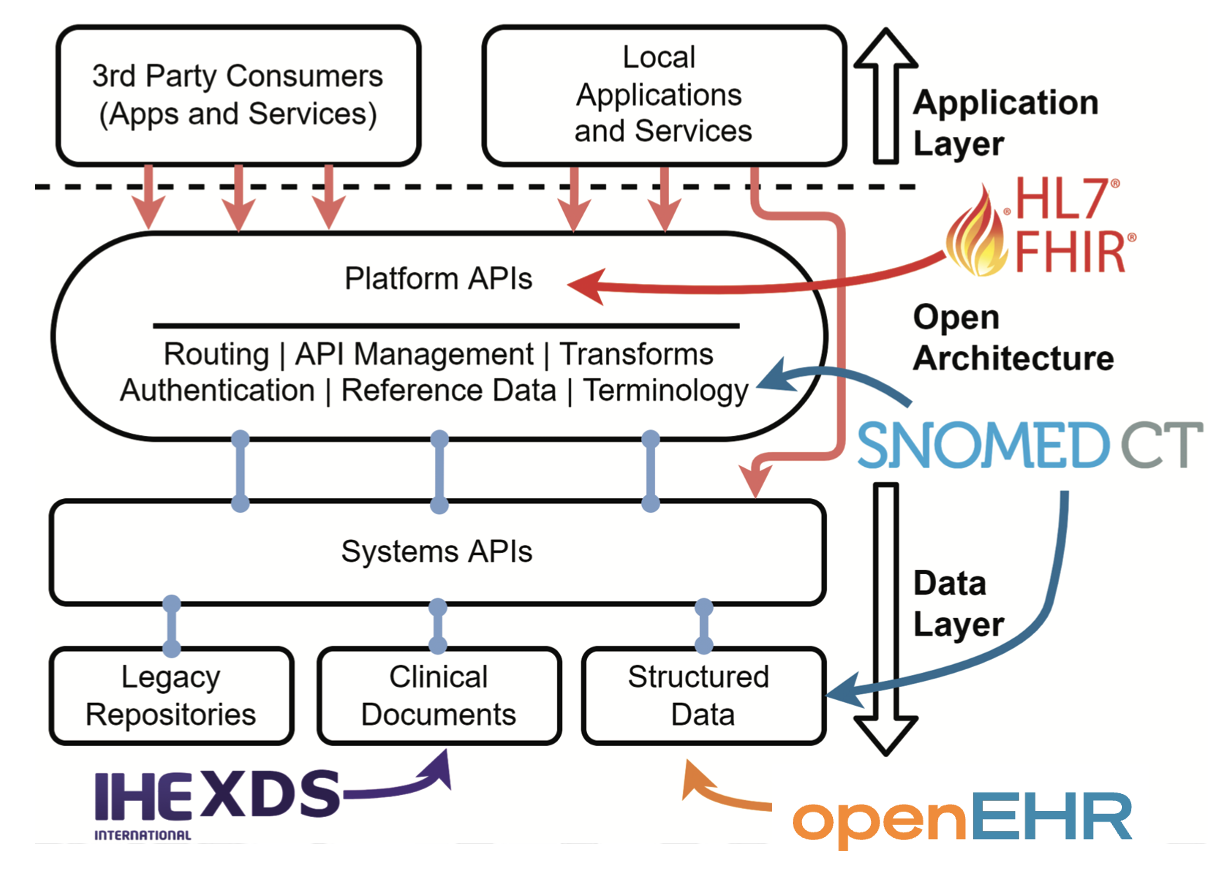
How can we solve the interoperability challenge together?
This is not a technological barrier, but rather one of clinical modelling. Although there is an extensive library of openEHR archetypes and templates already available and constantly expanding within the CKM, there are still a number of clinical specialities which require modelling.
Within my speciality of trauma and orthopaedics I see an important and innovative role of the British Orthopaedic Association (BOA) as a vehicle to assist and scale up the clinical modelling tasks through collaboration with other surgical subspecialties including royal colleges and surgical speciality societies, to produce these semantic open data persistent standards underpinned by openEHR clinical models. To further enhance this and to drive rapid and comprehensive uptake of modelling tasks by the clinical modelling community, it could be part-funded by commercial software suppliers who would benefit from using the outputs via the CKM library. Therefore, producing a comprehensive self-sustaining and updated archetypes, templates and models life cycle. This symbiotic relationship would drive improvements in clinical care and advance healthcare information technology.
If we could achieve this then all the clinical models from within the CKM can be reused openly and freely, whatever the situation, and cases would be independent (vendor neutral) to the application/software. Software developers could then be given the freedom to innovate on the user interface, rather than getting bogged down by the complexities of modelling the clinical discourse. Software engineers could focus on building apps – which are co-produced with patients and healthcare workers – that are fit for purpose.
I believe the NHS is on the verge of identifying and prioritising standards in healthcare data interoperability. Let’s hope the policy makers have a better understanding of the key standards of openEHR, HL7 FHIR, SNOMED-CT and how they fit together to support interoperability and beyond.
In order to create the right data environment for the future, we all have to work together: not only healthcare professionals and their organisations, technicians, vendors, standardisation bodies and interest groups but also public bodies who can create the conditions to embrace international standards (openEHR) and support the collaboration between communities behind them.
Final thoughts?
As a frontline clinician working in the NHS, I believe openEHR is one of the most important standards for solving the interoperability challenge. openEHR provides that data persistence layer allowing for longitudinal health records, but also helps clinicians to focus on patient safety, patient care and patient satisfaction. Although other standards are required – including FHIR – to patch together disparate and heterogenous data and applications, FHIR won’t in itself solve this challenge.
We have built up decades of technical debt due to commercial healthcare digital systems building their proprietary siloed applications that are not semantically interoperable with each other. We now have the technical standards (openEHR) and we should focus on building and scaling up the clinical modelling efforts across the health and care landscape to truly move the needle in digitising electronic health records for the future.
Leave a Reply